
VecML RAG System
Advanced Retrieval-Augmented Generation Platform for Enterprise Intelligence
System Overview
VecML's RAG system represents a breakthrough in enterprise AI, combining sophisticated retrieval mechanisms with state-of-the-art generation capabilities to deliver precise, contextually relevant responses.
System Architecture
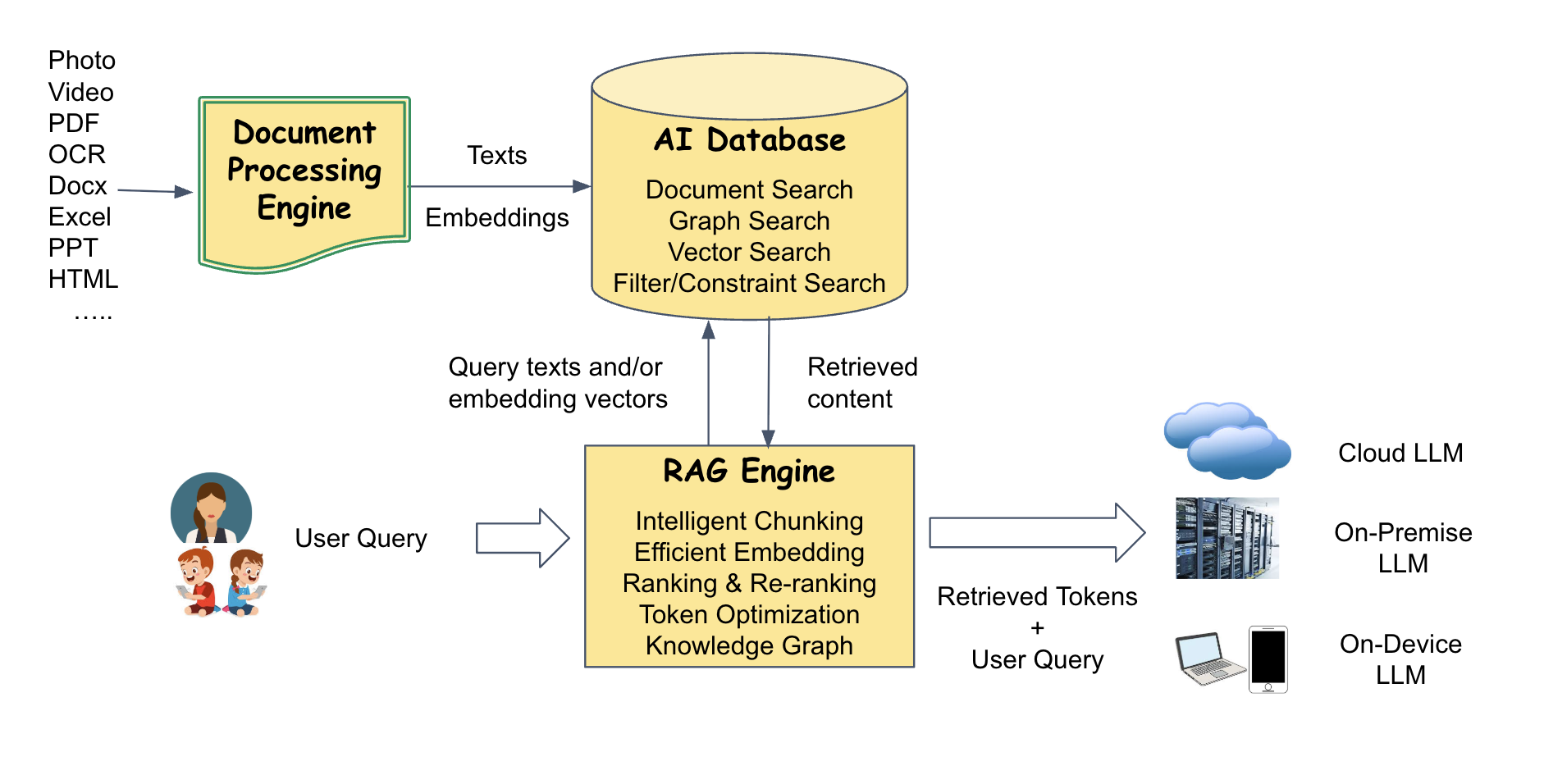
Our RAG architecture seamlessly integrates vector databases, knowledge graphs, and neural retrieval systems to provide unparalleled accuracy and relevance in information retrieval and generation.
Key Features
Robust File Parser
Support for parsing various file types including PDF, DOCX, TXT, JSON, PPTX, CSV, HTML, and more. Robust for unformatted and unstructured data.
Hierarchical Retrieval Strategy
Advanced search with hierarchical retrieval strategy to retrieve the most relevant context in documents
Multimodal Supported
Support documents with multimodal resources such as figures, diagrams, charts, and more.
Real-time Processing
Sub-second response times with enterprise-scale performance with our high-performance vector database
Try Live Demos
Experience the power of our RAG system through interactive demos and comprehensive API testing.
Web Chat Interface
Try our intelligent chat interface powered by RAG technology. Ask questions and see how our system retrieves and generates accurate responses.

RAG API
Explore our comprehensive API documentation and test RAG endpoints with your own data and queries.
Function Introduction
Discover the comprehensive suite of RAG capabilities designed for enterprise AI applications.
RAG System
Our sophisticated RAG system employs multi-level retrieval architecture with ensemble algorithms, multi-scale strategies, and intelligent document analysis for superior contextual understanding and response accuracy.
Multi-Scale Retrieval Strategy
Chunking Strategies
- • Auto adjusted chunk sizes
- • Semantic boundary-aware chunking
- • Overlapping context windows
- • Hierarchical document structure
Retrieval Pipeline
- • Initial recall with broad search
- • Post-retrieval context filtering
- • Advanced reranking algorithms
- • Relevance score optimization
Multiple Algorithm Ensemble
Retrieval Algorithms
- • Dense vector similarity search
- • Sparse keyword matching
- • Hybrid sparse-dense retrieval
- • Graph-based entity retrieval
Smart Ensemble
- • Weighted algorithm combination
- • Dynamic weight adjustment
- • Query-type specific routing
- • Performance-based optimization
Intelligent Document Analysis
Content Understanding
- • Semantic structure analysis
- • Entity and relationship extraction
- • Topic modeling and categorization
- • Cross-reference detection
Enhanced Processing
- • Context-aware preprocessing
- • Metadata enrichment
- • Quality scoring and filtering
- • Adaptive indexing strategies
Intelligent Multimodal RAG
Advanced multimodal processing that automatically detects, understands, and retrieves complex visual content including unparseable charts, framework diagrams, technical illustrations, and embedded multimedia from documents.
Automatic Visual Content Detection
Smart Detection
- • Embedded charts and graphs in PDFs
- • Technical framework diagrams
- • Process flow illustrations
- • Data visualization components
- • Architectural diagrams
Content Analysis
- • Chart type classification
- • Data extraction from visuals
- • Relationship mapping
- • Context-aware interpretation
- • Cross-modal content linking
Real-world Processing Examples
Complex PDF Charts
When a PDF contains an unparseable financial chart or technical diagram, our system automatically detects the visual content, extracts key data points, understands the chart type and relationships, and retrieves this information when relevant to user queries.
Framework Architecture Diagrams
System architecture diagrams, software frameworks, or workflow charts are automatically analyzed to understand component relationships, data flows, and hierarchical structures, enabling intelligent retrieval of architectural information.
Embedded Analytics & Reports
Business reports with embedded charts, performance dashboards, or analytical visualizations are processed to extract insights, trends, and key metrics that can be retrieved contextually alongside textual information.
Context-Aware Multimodal Retrieval
Smart Matching
- • Query-to-visual content alignment
- • Cross-modal semantic understanding
- • Relevance scoring for visual elements
- • Contextual visual retrieval
Enhanced Response
- • Visual content integration in answers
- • Chart data synthesis with text
- • Multi-format response generation
- • Source attribution with visuals
Data Parser
Advanced document parsing and preprocessing capabilities for structured data extraction and indexing.
Supported Formats
- • PDF, DOCX, TXT documents
- • JSON, XML, CSV data
- • HTML web content
- • Structured databases
Processing Features
- • Automatic text extraction
- • Metadata preservation
- • Content chunking
- • Format standardization
Knowledge Graph Enhanced RAG
Leverage knowledge graphs for enhanced context understanding and more sophisticated reasoning capabilities.
Graph Features
- • Entity relationship mapping
- • Semantic connection discovery
- • Multi-hop reasoning
- • Dynamic graph updates
Enhanced Capabilities
- • Contextual entity understanding
- • Cross-domain knowledge linking
- • Improved factual accuracy
- • Complex query reasoning
Benchmarks
Comprehensive performance analysis demonstrating VecML RAG's superior capabilities compared to industry leaders across multiple datasets.
RAG Performance Comparison
Accuracy on LiHua Dataset (%)
Performance comparison across different token limits and embedding models with GPT-4.1-mini as the LLM.
Dataset from: LiHua-World Dataset
Scroll horizontally to view all columns
| Tokens | Best VecML | OpenAI |
|---|---|---|
| Best | Large (256) | |
| 400 | 75.20 | 72.53 |
| 800 | 80.22 | 73.47 |
| 1600 | 82.26 | 77.71 |
| 6000 | 85.87 | 80.85 |
📱 Mobile View: Showing best VecML performance vs OpenAI. View on desktop for all model comparisons.
Consistent Improvement Across Token Configurations
VecML RAG demonstrates consistent improvement across all retrieved token numbers compared to closed-source OpenAI File Search Assistant. From 400 to 6000 tokens, VecML maintains a 2-5% accuracy advantage while being up to 550x faster in processing speed.
Significant Improvement Over Graph RAG Solutions
VecML RAG shows significant improvement compared to LightRAG and MiniRAG, achieving 29.87% better accuracy than LightRAG and 31.79% better than MiniRAGat 6000 tokens. This demonstrates superior performance over existing Graph RAG implementations.
Robust Performance with Embedding Model Flexibility
VecML RAG is robust across different embedding models, achieving comparable results even with smaller and less powerful embedding models. The 0.2B local model (384 dim) delivers competitive accuracy while maintaining exceptional speed, making it ideal for resource-constrained environments without sacrificing performance.
F1 Score on CRUD Dataset
F1 Score comparison on CRUD dataset tasks with different LLM models.
Dataset from: CRUD Dataset Paper
Scroll horizontally to view all columns
| Task | VecML Best |
|---|---|
| GPT-4o | |
| QA Doc 1 | 75.10 |
| QA Doc 2 | 63.52 |
| QA Doc 3 | 59.05 |
📱 Mobile View: Showing VecML's best F1 scores. Desktop shows full comparison with CRUD-RAG.
CRUD Dataset Insight: VecML RAG demonstrates consistent superiority over CRUD-RAG across all document QA tasks, achieving 100% win rate with an average improvement of 7.7% in F1 scores.
RAG Latency Comparison (1600 tokens)
Speed comparison showing VecML's superior performance efficiency
Scroll horizontally to view all columns
| Process | VecML Best | OpenAI |
|---|---|---|
| 0.2B Best | File Search | |
| Embed + RAG | 0.03s | ~11.3s |
| RAG Only | 0.02s | ~11s |
📱 Mobile View: VecML's fastest speeds vs OpenAI. Desktop shows all embedding model comparisons.
Performance Insight: VecML RAG achieves up to 550x faster performance compared to OpenAI's File Search while maintaining superior accuracy across all token configurations.
Ready to Transform Your AI Capabilities?
Experience the power of VecML RAG system and revolutionize your enterprise intelligence.